More Ethereum Workshops
In conjunction with Hubba Thailand, for more details click here.


Having declared bitcoins in particular and cryptocurrencies in general to be a load of rubbish only to see bitcoins triple in value since I posted, I suppose I should be feeling quite silly by now. All I had to do was throw my life savings into bitcoin and I’d be sitting pretty. The expression “get with the program” comes to mind.
I remain cynical about cryptocurrencies, but blockchains are here to stay and smart contracts seem to be the problem they solve. So, in the past few months, I’ve been getting up to speed on them, and am now sufficiently accomplished that I delivered a workshop on them and have been asked back for another.
What makes me think that smart contracts have a future in a way that cryptocurrencies don’t? Certainly, the amount of computer power needed to do simple things remains ludicrous, and, for many applications, it’s difficult to see what a decentralised ledger brings that a single, centralised database doesn’t already deliver. There are plenty of sites out there doing smart-contracty things, but which work without the added complexity and overhead of blockchains – gambling sites such as betfair spring to mind.
It is also difficult to work out how to make money out of smart contracts, per se. Sure, there’s mining But rather than contribute any actual innovation, all miners do is buy a whole bunch of hardware and get a fast and juicy RoI. That RoI only happens, however, if smart contracts are doing something.
The main thrust appears to be tokens. Get some digital content together and sell it for tokens rather than real money. Other than being cool, I’m again not sure what this adds to an existing digital content business. If your tokens are tradeable only for your own products, then all you’re doing is pre-selling your product (and maybe skim a transaction fee if a secondary market comes into being). If your tokens are tradeable on like-minded sites – i.e., your competitors – then you’re putting yourself under a lot of new pressure.
So what’s left? Keeping track of who owns which item of digital content is a huge area, waiting to happen. Another is sharing data between parties who have an interest in sharing data, but who don’t trust each other because they’re competitors.
To me, this last area is the one that holds most potential. As an example, take consumer credit bureaux. The idea is that the banks and credit card companies pool data to create a score for each customer. That score is part of potential lenders’ decision making processes: people who don’t have a history, or who do have a history, but it’s a bad one, end up paying more interest.
Today, these systems are implemented as single, centralised databases. That presents a single point of attack for a hacker. Moreoever, there’s an incentive to steal data: the dataset on offer is very valuable. Anyone hacking into a consumer credit bureau could steal a whole bunch of identities, and manipulate records to gain credit at rates to which she’s not entitled – and then run with the money.
The decentralised, cryptograhic nature of blockchains goes a long way to protecting from this kind of theft and manipulation. I suspect there are very many similar applications out there. It may not be sexy, but as a B2B application, this type of sharing will run and run.
In my previous post, I concluded that cryptocurrencies face major hurdles, but that blockchains offer promise. In an earlier series of posts, I concluded that data centres will diverge into three different types, one of which is a highly distributed global computing network that consists of low-powered computers mounted directly on solar panels.
I also said that batteries are horrid, so that global network of low-powered computers should run without batteries. That means that they’re off at night, which in turn led to a follow-the-clock type of computing in which, as the day ends in one place, the computing gets pushed ever westwards. However, I didn’t specify the mechanics of how such a grid would work, and although I think it’s do-able – and interesting to do - it’s feat a piece of engineering.
It now occurs to me that blockchain mining is that feat: the perfect application for such a network.
First, by design, all blockchain networks are distributed. There are lots of copies of the relevant blockchains living on lots of computers, and only some of those computers will respond to any given request. It doesn’t matter which ones. It doesn’t matter why a given computer fails to respond: it could be busy doing other things, it could be switched off. It could be that it’s night so the computer’s powered down as there’s no sunlight to power it.
Second, by design blockchains are fault-tolerant. If a computer fails half-way through mining, it doesn’t matter: that mining is being done by multiple other computers, and the expectation is that only a few will produce a correct result. Whether a computer drops out because it can’t produce a result in time or because a cloud passed in front of the sun doesn’t matter.
Third, storage is already designed in. The original thought was that there would be multiple copies of any given datum (photo, song, whatever) distributed around the network in such a way that there will always be a copy available somewhere where the sun is shining. Unfortunately, designing highly distributed file systems is quite an undertaking. But, with blockchains, that design is done and built-in.
So the idea is this:
1. Find NGOs that install solar panels in poor countries.
2. Find other NGOs that are keen on bringing computing to poor countries.
3. Attach Raspberry Pi computers to the solar panels, perhaps with a blockchain ASIC to speed up the processing - see here.
4. The computers attached to a given panel will use some, but not all the power. There will be plenty left over, so the communities get free power.
5. The community will get a share of the income from the bitcoin mining.
6. SolarRaspberryMining will get the remainder of the income from the bitcoin mining.
A few specifics, just to demonstrate that this is feasible.
The Raspberry Pi Compute 3 uses the ARM CMOS chips, which use tiny amounts of power compared to mainstream server chips – the model 3 uses 5.1v @ 2.5A, which amounts to less than 8W, which corresponds to about 15cm * 15cm of solar panel. Assuming a panel is 1 square meter, that could mean up to about 40 Raspberry Pi computers per solar panel.
There are ASICs to speed up blockchain processing, and speed is probably important. Those ASICs will most likely be quite power-hungry, so that reduces the number of units per panel. To avoid heating (more accurately, heat dissipation) problems, and to leave power spare for the community, say half a dozen Pis+ASICs per 1m2 panel.
That model of Raspberry Pi is about USD40, and that will probably be USD100 by the time we’ve added wireless and an ASIC. Allow for the usual fudge factors, and we’re probably looking at USD1,000 per panel. That buys half a dozen Raspberries, on a panel, and all plugged in, installed, tested and the like. It doesn’t buy the panel.
There is R&D to be done: working out how to attach the PIs, customizing the OS for various blockchains, and generally making sure the whole lot works. And then there’s the issue of finding organisations to work with. So overall, this is quite a project. If you think it’s got any legs, please get back to me on chris.maden [at] cpmc.com.hk, and we’ll see if there’s a way to make it work.
When a friend of mine first enthused to me about bitcoins in 2010, my response was muted. “Great idea,” I said, “for keeping track of who owns a particular copy of an item of digital content, but forget about it for currency.” He either didn’t understand or didn’t want to understand why I said that. Now, it seems I wasn’t far wrong.
I’ve been consulting to central banks and working in IT security for payments systems for over a decade. Bitcoins first came on to the scene about eight years ago, and were predicted to have put dinosaurs like me out of jobs by, er, seven and a half years ago. That hasn’t happened yet – though maybe it will. But I think there are good reasons why it won’t, and here they are.
Before I get started, two things. First, Satoshi’s paper which launched cryptocurrencies wasn’t ambitious – he wanted to disintermediate financial transactions, not turn the world on its head. However, the stampede of venture capitalists and the like are ambitious – otherwise, they wouldn’t be in the game – and this post is directed at them. Second, “cryptocurrency” is difficult to type and hard to read, so I’ve used “bitcoin” as a placeholder to mean cryptocurrencies in general.
That said, to business. The reasons I think bitcoins are doomed are to do with the nature of currency, which to me comes in two parts.
1. Repository of Future Value
The idea that money is a repository of future value may seem unconventional. After all, no less an authority than wikipedia says that money is a medium of exchange, a measure of value, a standard of deferred payment and a store of value, not a repository of future value. However, I defend my definition at a trivial level by observing that I’ve done no more than combine the latter two of wiki’s definitions, and at a deeper level thus:
The banknote in my wallet is worth nothing until I spend it: a future event. In quotidian transactions, I give you that banknote and you give me a good or service. So I realise the value of the note by transferring the promise from me to you – and on it goes. However, some future owner of the banknote may go to the entity that issued the banknote and demand payment. At that point, the issuer has to make good on the promise by giving the bearer goods or services.
The common understanding is that, at that time, a banknote will derive its value from the assets by which it was backed – until a few decades ago, gold. So a citizen could stroll into a government office and redeem her banknote for an appropriate share of the government’s assets.
As early as the late nineteenth century, it had become obvious that no government could or would liquidate its assets and carve them up amongst the citizenry. The dissolution of the Gold Standard in the Bretton Woods conference and later legislative moves (I’m told it took the US until 1976 to get around to de-legislating gold) were nothing more than bowing to the inevitable. And this is because modern governments don’t run on assets, but debt. And a modern currency’s value is determined by the ability of a government to raise taxes to service that debt. That ability is contingent to some extent on the government’s assets. But it is far more contingent on the government and its citizens honouring the social contract which binds them: people paying their taxes, and the government spending them in broad accordance with its citizens’ wishes. This is of course imperfect at the best of times, but that’s why America and Europe, with strong institutions and firm social contracts, have currencies that are valued, and why Zimbabwe didn’t.
The problem that bitcoin faces is that it’s not a government. It has no ability to compel people to pay taxes. It therefore has no ability to deliver on the value when the day comes. The sole and only way of realising the value of a bitcoin is to find someone who is willing to exchange the bitcoin for goods or services. It that person can’t be found, the bearer is stuck. She has no means to compel, no rights as a citizen.
Now, I’m not saying that governments don’t fail; that citizens don’t get screwed – look at the aftermath of the Global Financial Crisis of 2008, or anywhere that’s gone through hyperinflation. But these are exceptions. Nearly all of the time, bearers of conventional currency have recourse: they have rights and the means to enforce them. Bearers of bitcoins are in a legal vacuum.
2. Transfer of Future Value
Or, to put it simply, payments.
People expect – with good reason – that payments are fast, cheap and reliable.
A typical payment in a modern payments system, using the SWIFT / ISO20022 messages or using ATMs with ISO 8583, is in the order of 600 bytes of data – about as long as this paragraph – and follows this sequence: make sure I have the funds available, remove (or block) them from my account, credit them to your account. This can be done in microseconds. The slow part is the communications, which can take a few seconds for credit cards, and a few milliseconds for touch-and-go (NFC) payments.
Cryptocurrency payments are neither fast nor cheap. This is because the underlying technology, the blockchain, is neither fast nor cheap by deisgn. A typical blockchain is about 130 Gb. The processing of a blockchain transaction is inordinately complicated, requiring the generation of very big prime numbers, which are to be vetted for coincidental adherence to a given set of criteria. Most numbers don’t comply, and are discarded. One of those which does comply will replace that already in the blockchain. This uses vast amounts of computer power: if all the world’s trillions of transactions were processed by blockchains, there wouldn’t be enough power left over to switch on a light bulb.
There are ways of pruning the blockchain, and there are cryptocurrencies out there which are moving away from generating huge prime numbers for each and every transaction. But they’re all based on public/private key encryption, and this is computationally far more demanding than conventional payments. (For the record, credit cards and ATM payments typically use symmetrical keys, which require a couple of orders of magnitude less of computer power. The symmetric keys are periodically updated using public/private key encryption.)
Yes, there are special purpose chips and whatnot. But it all comes to the same thing: more computing power means a higher cost per transaction, and whatever advances are made that reduce the cost of processing cryptocurrency transactions will carry over to conventional payments: the latter will always be cheaper.
To put it another way: the gold standard of a modern payment is that you can swipe your card or phone while passing through a turnstile without breaking stride. To do this, the transaction must be cheap, simple and very fast. No cryptocurrency comes close.
However, even if there’s a sudden change in the laws of physics, there’s another major hurdle. Regulators.
3. Protecting the Public
As soon as cryptocurrencies become mainstream, regulators will leap into the fray. Cryptocurrencies are very useful tool for money-laundering sleuths as they contain a complete transaction history. However, there is no way of associating a particular wallet with an actual human being or organization – hence the current popularity of cryptocurrencies amongst crooks. But as soon as the problem becomes big enough – and I’m told it already has – regulators will mandate that cryptocurrency providers perform the same checks on their customers as banks as are required to on theirs. Setting aside that anonymity was a stated aim of cryptocurrencies, so Know-Your-Customer rather defeats that point, the cost structure in this respect is going to be the same as for conventional payments.
—
In summary: the same regulatory overhead, a much higher per transaction cost due to increased computation, and no recourse. So bitcoin bearers pay more and get less. Not an attractive proposition.
I said all this eight years ago, and here we are, eight years on. Cryptocurrencies have faded from view. Yes, they’re still there, yes, there’s still some action, and yes, bitcoins are trading at about USD4,000 per coin. But there’s little sign that they’ve revolutionized the world’s financial markets.
What has happened is a sudden rush of interest in the underlying technology for what I though eight years ago was the problem this particular solution seeks. Blockchains are decentralized, secure ledgers that contain entries detailing who owns what. In the case of the original bitcoin, the “what” was money. For the reasons above, I never thought this had much promise. But for movies, books, music and the like – now known by the ghastly term ”intellectual property” or IP - there is a rapid trend that the primary delivery mode is digital. And that creates the problem of validating that the person who views / listens to the work, owns it.
The solution being touted is that each person has a wallet full of tokens, and each token gives her certain rights over a certain digital copy of a given work. That has some mileage. The problem is that the value of digital content is converging on zero. That means there’s precious little money in tracking who owns a particular copy of a work. Which means that we have a problem, a solution, an no way of making it pay. Back to square one.
* Thanks to Gavin Costin for his comments on the original post.
In this series, I’ve tried to unload everything that I see as being wrong about the way we think about, design and build data centres. I’ve said that my perfect green data centre is not a data centre at all, but consists of solar panels, with computers mounted on them, installed on people’s roofs. A second-best is the ultimate air containment monocoque. And, as the least good, a bodge job for colocation.
But, at a higher level, nothing I’ve said addresses the fundamental problem, which is that computers turn electricity into heat.
To some extent this will always be the case, but it needn’t be the case to the extent that it is. Nearly all servers use NMOS chips, and NMOS chews power. There’s nothing to be done about this. The basic unit of all digital technology is the transistor. NMOS requires a transistor and a resistor to create the most basic logical circuit (an invertor), and more complex functions similarly require resistors. Resistors dissipate unwanted electricity by turning it into heat. So NMOS chips necessarily turn electricity into heat.
But the computer chips that power your phone are not NMOS – and your phone battery would last minutes rather than hours, and your phone would burn a hole in your pocket if they were. The chips in your phone are CMOS. And CMOS consumes an order of magnitude less power.
This is because CMOS chips use almost no resistors. For every one transistor / resistor pair in NMOS, there will be two transistors in CMOS. Those transistors only use power at the instant a state changes, whereas resistors use power nearly half the time. (In an NMOS invertor, whenever the input is 1 and the output is 0, the resistor is active. Assuming on average that the invertor will spend equal amounts of time in both states, and the resistor’s pumping out heat half the time. In a CMOS invertor, one transistor is on and the other is off, and neither dissipates heat, so the average amount of power pumped out is close to zero. Similar cases apply to more complex functions.)
As transistors take up more space than resistors, and are more complex, CMOS packs fewer logical functions into more space. Because the construction is more complex, the yield – the proportion of correctly functioning chips coming off the production line – is lower, so CMOS are more expensive. But the power consumption is much, much lower.
Conversely, NMOS chips pack more computing into less space, and are less costly than CMOS chips of the same die size. Hence their ubiquity, especially in server grade equipment. The downside is that resistors turn electricity into heat and transistors don’t, so NMOS chips emit a great deal more power.
But the limiting factor in solar power is the insolation: the amount of solar energy that reaches the ground. This, for any given part of the world on any given day is fixed. Even if we recover 100% of that solar energy – and we never will – the 1,350W per square meter that comes from the sun in the tropics will power at most two or three off-the-shelf commodity NMOS servers. Those two or three servers will occupy much less than a square meter.
But that same 1,350W will power maybe a dozen CMOS servers. And the resultant extra density more than compensates for the fact that CMOS chips tend to be less powerful than NMOS chips.
In other words, there’s an imbalance. NMOS consumes solar energy faster than we can generate it; CMOS uses solar energy at roughly the same rate per square meter that we can generate it. And because we’re using that energy to power state changes – which is what matters - rather than to preserve states – which shouldn’t take any energy at all - we pack in far more computing into each square meter than we can with NMOS.
So the perfect green data centre consists of PV panels on people’s roofs, with CMOS servers attached, connected by wifi towers or fibre as appropriate, and with data replicated at time zones +8 and -8 hours away (or +120 and -120 degrees of longitude) so that computing follows the clock.
Or, in other words, the perfect green data centre consists of our planet Earth itself, shorn of the ugly concrete boxes that turn electricity into heat. Who’s up for building it? I’d be delighted to hear from you – chris,maden [at] cpmc.com.hk.
I’ve seen some amazing items of equipment in colocation data centres. The winner has to a drum printer, but I’ve seen passive 4-way hubs, any number of free-standing modems, more desktops than I care to remember, and that’s before we get to the tape drives, optical jukeboxes and voice recording equipment. And that’s only the digital stuff. The analogue equipment for telephony comes in shapes and sizes of which Heath Robinson would be proud.
So, although pre-mounting stuff in trays and having robots insert those trays into a sealed monocoque of the type I suggested in the last post may work 90% of the time, the 10% will kill any attempt at robotics. The range of things that goes into a colocation data centre is just to vast for anything but the current row and aisle, human-access data centre. Having untrained IT guys clambering around a vertical chamber, laden with heavy and expensive equipment, is a non-starter.
As to robots, forget it. They’re too expensive to be cost effective. And human incursion is binary: one either designs for it or doesn’t. If there are likely to be even a few of incursions a year, one must design for it, and one reaps the costs of both the robots and the infrastructure needed to deal with humans.
So what is there to do? Quite a lot. They’re all little things, and most of them have to do not so much with the engineering, but with the dynamics of how colocation providers interact with their clients.
On the engineering, insulate your building, deploy geothermal piling, install hot or cold aisle containment, use evaporative cooling, but also, look at the load. It is much more energy efficient to cool three 4kW racks than to cool a single 10kW and two 1kW racks, yet clients arrange their IT in the latter way all the time. Put intelligent PDUs on each and every rack, monitor the heck out the whole white space with temperature sensors, and re-arrange your client’s equipment to balance the temperature. Yes, there are constraints on cable length and demands of proximity, but even within these, the equipment layout can be optimized.
To do this, the contracts need to be restructured to reward the clients for good behaviour. Most colocation contracts I’ve seen (and I’ve seen many) rather than rewarding the client for good behaviour, reward the data centre operator for their colocation clients’ bad behaviour. It does not have to be this way. Colo providers sell space, electricity, network bandwidth and time. Break the electrical component down into base IT load (which is fixed) and cooling (which can almost always be reduced), and you incentivise the client to work with you to reduce his heat load.
Don’t allow your clients to use cages. I’ve mapped out the topology of enough networks by looking at the backs of racks to know that it can be done – but I had keys so didn’t have to peer through the grate. But the bigger points are that all IT estates consist of the same stuff – servers, storage and network - and unless you know what the hardware does and what the IP addresses are (yes, they’re supposed to be labeled…) knowing that the estate consists of servers, storage and networks is like knowing that a building consists of bricks, wood and metal. Furthermore, with virtualization technologies, the hardware is so abstracted from the network topology as to be almost irrelevant. So the cages serve almost no useful purpose in securing the estate. Yet cages are terrible for data centres: they screw up the airflow, stressing the cooling system. If anything, they offer a false sense of security: the real threat’s at the end of the wire, not some guy photographing your racks..
And anyway, cold air containment systems provide most of the perceived security advantages of cages.
And then there’s the Network and Security Operations Centres. Here’s the next generation NOC/SOC:

I’m not advertising or advocating the Huawei 9 Mate – the picture’s just to make the point: the technology is already available to monitor all systems and alert people when unexpected things happen. It can tell if a human is in the white space, check that against whether or not there should be a human in the white space, and which part of the white space that human should be in. SNMP is hardly new and any half-decent DCIM will send text messages, e-mails and the like if it thinks a component is breaking. All those flashy monitors and screens in the NOC and SOC serve no useful engineering purpose.
And then there are the little things. Use LED lighting, not fluorescent tubes, and switch the lights off it they’re not needed. Stay away from CFCs if you have DX units. If you’re using evaporative cooling, there’s no chilled water so no need for a raised floor – so don’t install one. I think that there’s no need for any permanent staff in a data centre but, if you must have people there hard at it doing nothing most of the time, give them LED lighting, efficient air-con, too.
Plant a few trees.
And finally, source clean power. If you must offset, offset, but at least put a solar panel on the roof. If nothing else, it can keep the staff cool and in light.
Having concluded in the previous post that the best data centre is no data centre, in this and the next post I’ll go for the second-best options for a cloud service and colocation data centres.
The reason I distinguish between cloud and colocation is that the IT in a cloud data centre is much more homogenous than that in a colo data centre. Where colocation tenants tend to pack their racks with all manner of stuff, cloud operators and internet service providers tend to buy thousands of identical of identical servers with identical disks, and identical network equipment. This opens possibilities.
The first is to keep humans out. Humans bring in dust, heat, moisture and clumsiness. We present a security risk. And we add a lot less to computing than we like to think.
If we are to keep humans out, what happens when things break? A simple answer, and one that I suspect will be the most cost-effective over the life-span of a cloud data centre, is “nothing.” Given the low cost of computer power, fixing a single broken server, disk or motherboard is hardly going to make a difference. That computer manufacturers no longer even quote the Mean Time Between Failures, a measure that determines the reliability of mechanical things, suggests that out of, say, 5,000 servers, 4,999 will be working just fine after five years.
If, however, we are going to insist on fixing things, how about robots?
I was told five years ago when I first thought of robotics in data centres, that robots in data centres would never work. For a colocation data centre, I came to agree. The best we can do would be to build a pair of robotic hands that are remotely operated by a human. This would keep the dust, heat and moisture out, but instead of having a weak, clumsy human bouncing off the racks, we’d have a strong, clumsy robot. On top of that, for remote, robotic hands to work, they need to be tactile, and to this day, tactile robotics costs some serious money.
But my friend Mark Hailes had a suggestion: for a cloud data centre, mount all the equipment in a standard sized tray with two power inputs and two fibre ports. Rather than have a fully-fledged robot, use existing warehouse technology to insert and remove these trays into and from the racks. There could be standard sized boxes, 1U, 2U and 4U, to accommodate different servers.
My friend Richard Couzens then inspired a further refinement, which is to have a rotunda rather than aisles and rows. This minimises the distances the robots have to move, and therefore reduces the number of moving parts, which ought to improve the reliability of the whole.
Finally, with robots doing the work, there is no particular need to stop at 42U: the computers can be stacked high.
Put these together, and we get a very different layout from that of a conventional data centre:
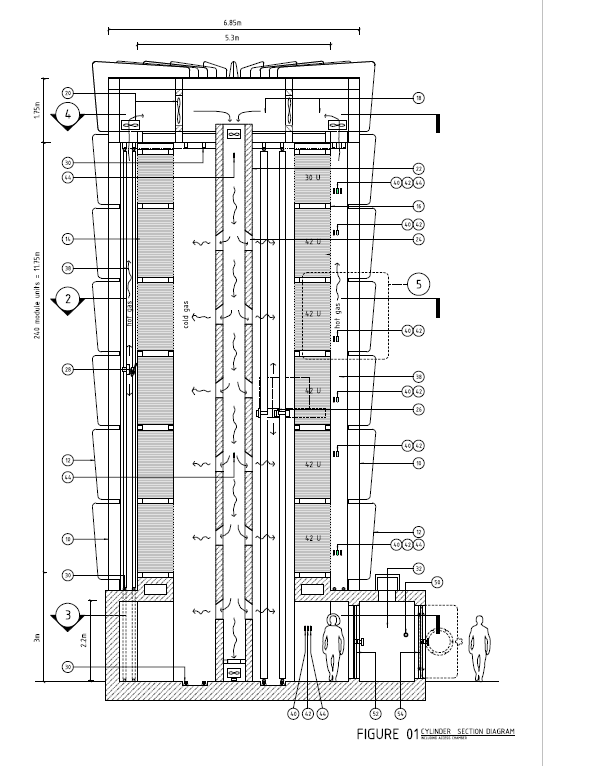
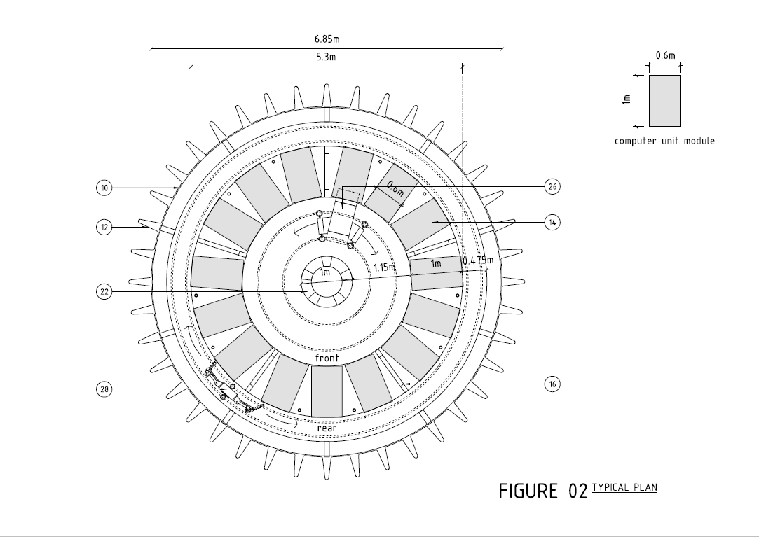
If that looks familiar, it’s because it’s the same layout I suggested here to take advantage of natural convection currents. So here’s the whole story.
Before operations, the tower will be populated with racks which are designed to receive trays. The racks will be fully wired with power and data. Human beings (as a group of humans can work more quickly than a single robot) will fill up the trays with computers and the racks with trays. When everything’s been plugged in, the humans leave. The entire tower is then sealed, the dirty air pumped out, and clean air pumped in. The tower will use evaporative cooling; that will be switched on and the computers powered up.
We only supply DC power. There is no AC in the tower, and consequently no high voltages. The robot (which is more of a dumb waiter than a cyborg) can be powered using compressed air or DC motors – that’s something for a robotics guru.
The tower is designed to be run for many years without human incursion. If something in a tray breaks, the robot will retrieve the tray and deliver it to the airlock, where a person picks it up and takes it away for repair or disposal. People outside the data centre will pack computer equipment into trays, insert the trays into an airlock at the bottom of the tower, from whence a robot will pick the tray up, transport it to its final location, and insert it.
When it’s time to replace the entire estate, the tower is depowered and humans can empty it out and build a new estate.
The robot uses the central core of tower. All it has to do is move up, down, around in circles and backwards and forwards. These are simple operations but nonetheless, mechanical stuff can break and does require preventative maintenance. When not in use, the robot therefore docks in an area adjacent to the airlock, so it can be inspected without humans entering the tower. As a last resort, if the robot breaks when in motion, or if something at the back of the racks breaks, a human can get in, but must wear a suit and breathing apparatus. That may sound extreme, but the tower will be hot and windy.
It may also be filled with non-breathable gas. I’m told that helium has much better thermal qualities than natural air, and filling the tower with helium would not only keep humans out, but would also obviate the need for fire protection. The lights (LED lighting, of course) would be off unless there’s a need for them to be on, and a couple of moveable cameras can provide eyes for security and when things go wrong.
Each tower would be self-contained. Multiple towers could be built to increase capacity. Exactly how close they could be, I don’t know. But this is a design that achieves a very high density of computer power in a very small area: that makes it suitable for places where land is expensive.
Last but not least, in this most aesthetically-challenged of industries, these towers would look really cool. So: Google, Facebook, Microsoft: run with it!
So far I’ve discussed the topology and engineering within a data centre. In this post, I take a big step back to produce a blueprint for any global internet provider such that, by combining follow-the-clock computing with a much lower-density arrangement, we get to a much lower carbon footprint.
I will now unpack that in reverse order.
Let’s start at the IT load. In an early post, I stated the ASHRAE A3 standard recommended thermal guidelines, which I have since assumed. But that’s not the whole story. Getting holding of the ASHRAE standards has become rather difficult as, like everyone else, they’ve become selfish with the information and want people to pay. However, there’s the link here guided me to the paper Clarification to ASHRAE Thermal Guidelines, which I believe is in the public domain, and which shows the full picture: although 18-27C is the recommended operating range of temperatures and <60% the recommended humidity, the allowable range is 5-40C / <85% (and, for A4, 5-45C / < 90%). Ask my laptop: computers can work in high heat and humidity and, if they’re solid state, can last for many years. Put a motherboard built to ASHRAE A4 standard in the middle of a room in the tropics, aim a fan at it, and it will run almost indefinitely.
However, in a data centre, we don’t have a single motherboard in the middle of a room. We have many motherboards. This leads to lots of heat being generated in a relatively small area, and the problem of cooling in data centres is not caused by the computers per se, but rather by our insistence on packing lots of computers into a small space. The more we spread the computers out, the easier they become to cool. If we spread them out sufficiently, and if they’re built to withstand a high intake temperature, all we need to do is extract the hot output air.
The reason that we pack them in is that, in the past, it was held to be important that the computers were close to the people they served. This meant that data centres were built in or near urban areas where land is expensive, so the extra cost of an expensive cooling system was justified on the basis that computers could be packed.
But things have changed. From a security standpoint, the farther away the data centre is from urban areas, the better. From the point of view of land-cost, likewise. And it is now far cheaper to run fibre to a rural area than to buy land in an urban area.
Next, let’s take 1,350W/m2 insolation as a physical constraint. I suspect that we’ll never do much better than 50% recovery, so we can generate, say, 650W/m2. One of the problems I’ve been tackling in the last two posts has been that our load has a much higher density: if we’re stacking ten servers to a rack, then for every 0.6m2 rack we need 6m2 of solar panel. Allowing for the fact that the racks themselves are spread out, I concluded that every m2 of rack needs 2.5m2 of solar power (whether PV or CSP).
Here’s my proposal.
The power from a single panel, 650W, is enough to power a mid-range motherboard with a few disks. So, rather than having a huge array of panels over there powering a whole bunch of low- to medium-density computing over here, put the computing where the sun shines. Assuming the motherboard is built to ASHRAE A4, the problem is not intake temperature, but extracting the heat. To address this, we design the motherboard such that all the hot stuff is at the top, and we put a couple of fans at the bottom to blow the heat out. We protect the motherboard from rain by enclosing it (hopefully in some low-footprint material).
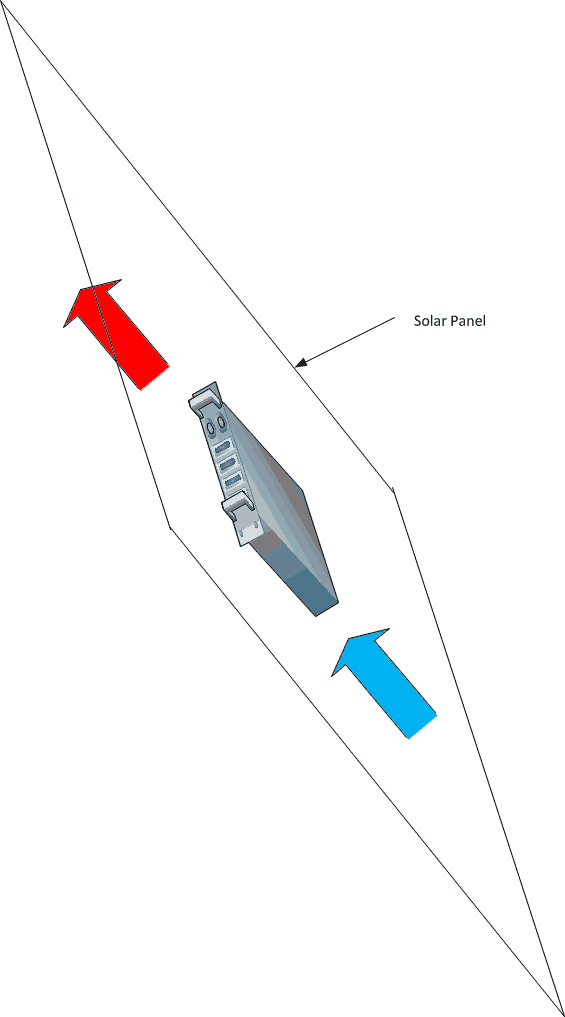
Okay, no prizes for the artwork. The rhomboid-ey thing is the solar panel, the computer’s strapped to the back, and the arrows indicate cool(ish) air coming in and hot air being blown out.
Or, perhaps, we have compute-panels and disk-panels, arranged in some repeating matrix:
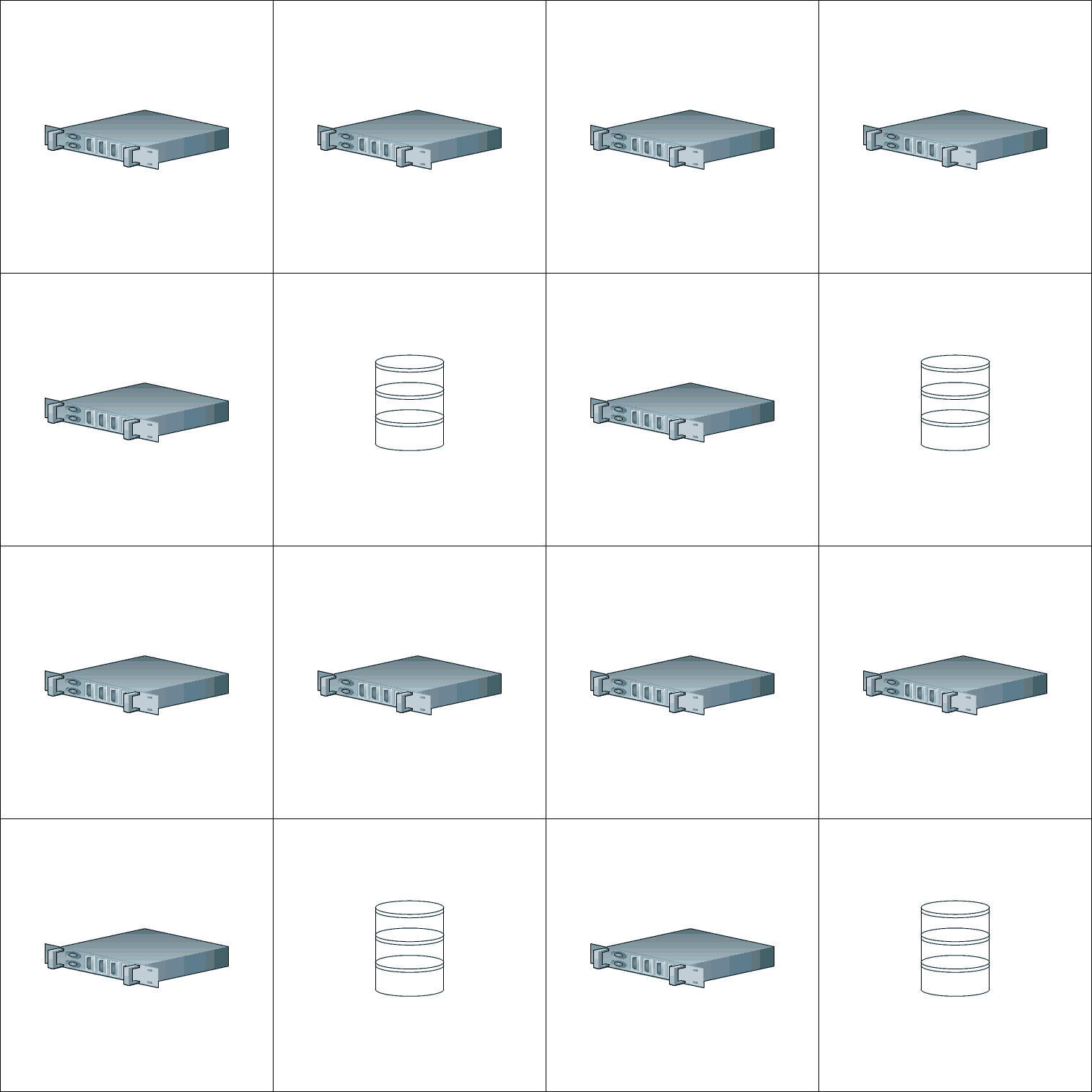
Each panel+motherboard is in principle self-contained. However – a problem for a mathematical topologist – panels should be interconnected in such a way that a cloud passing over doesn’t cause dead zone to zoom across the array. The entire array, and the weather, should be monitored so that, when it gets cloudy, selected computers can be de-powered depending on the extent of the darkness.
At night, instead of using batteries, de-power the entire solar-compute farm, and off-load the computing to the next solar-compute farm to the west. In the morning, computing will arrive from the sol-comp farm to the east.
Now let me push it further. In a world with starving people, it makes little sense to replace tracts of agricultural land with solar arrays when there are millions of small villages across the tropics that already have roofs. Put a few solar-compute panels on each roof, and interconnect them by sticking a wifi tower in the village. Pay the village or villagers not with rent, but by providing each house with a battery, some LED lights so that the children can study at nights, and an induction cooker so that villagers don’t cut down trees for firewood. Recruit a couple of villagers and put a NOC/SOC on their tablet to give them responsibility for their own village solar-compute array. Make this part of a training and recruitment program so that the NOC/SOC have a future that goes beyond installing the solar-compute panels and fixing them when they break.
If computing is going to follow the clock, sooner or later it’s going to fall into an ocean. Most oceans have land to the north or south, but the Pacific Ocean is a particularly large hop. In the north, it’s possible to string data centres along the west coast of North America and the east coast of Eurasia, and in the south, the Polynesian archipelago could keep the bits and bytes being crunched.
That covers the edges. For the ocean itself, with the oil industry in its death throes (what a shame they don’t use all that money and power to switch business models to renewables rather than sticking with the cook-the-planet model), quite a lot of large floating structures – oil rigs, supertankers and the like – will be available on the cheap. They could form a string of permanently moored data centres that run off some combination of wave, wind and solar power.
Does this sound more like science fiction than engineering? Perhaps. But nothing in the above is beyond the reach of today’s technology and engineering: we can design motherboards, chips and disks that run reliably in hot and humid places; PV technology is already almost there; the underlying control systems, network connectivity and ability to shunt data are also already there. What’s lacking is not the engineering or the technology, but the will. Google, Amazon, Facebook, where are you?
Not on this blog. So, in the next post, I’ll take all the bits and put them together in a more conventional, less frightening way,
Previous Next
In the previous post, I came to the sad conclusion that harnessing sunlight with PV panels is not feasible as a reliable, green power source for a 24/7 data centre. It is at best an auxiliary power source, or a boost to the primary source during daylight hours.
This is because nature is not very good at storing electricity. But nature is good at storing other types of energy, and is very good at storing heat. And this is where Concentrated Solar Power comes in. There’s a detailed wiki article here; the short story is that CSP uses multiple mirrors to reflect the sun’s heat to a small point. That point in turn heats up molten salts, which in turn super-heat water to drive a conventional steam turbine.
The downside is that where PV has a single conversion – a photon knocks an electron free – CSP has multiple conversions – from solar radiation to heat to kinetic motion which drives a turbine and finally, via induction in an alternator, to electricity. Hence, although each of these steps can be very efficient, the theoretical limit on efficiency is going to be lower. However, as even domestic solar water heaters are 70% efficient, we’re starting at a much higher baseline than PV.
The joy of this is that rather than battle nature by trying to store electricity, CSP opens the possibility of storing the heated molten salts in a tank for release during the dark hours of the night. Insulating a tank is much easier than persuading molecules to host itinerant electrons. And, as I keep saying, there’s more to greenness than efficiency. Building a tank to contain hot stuff requires far fewer nasty chemicals than batteries. In addition, the tank’s life time is more or less indefinite, whereas batteries die.
Given these tensions, the overall viability of CSP is still up in the air. Predicted efficiencies for CSP are below theoretical ones, and the costs are 2-3 times those of PV panels (albeit, PV panels without the battery packs). So this is a technology that’s still not quite ready for the big time. But because energy is stored as heat, CSP offers the promise of 24/7 solar power without the horrors of batteries.
The wiki article appears to be 2-3 years out of date. More up to date information is on the National Renewable Energy Laboratory website. This suggests another problem, which is that the power densities from CSP just aren’t in the same league as those from PV panels. The site has an index of projects here, and most CSP plants cover large areas.
And this comes back to the nature of solar radiation: even if we recover up to 60%-70% of insolated energy, and even if we find ways of storing solar energy overnight that are 80% efficient, we still need a rainy-day buffer. Put this altogether, and the 1,350W / m2 diminishes fast. 70%*80% = 56%. Add a rainy-day buffer of a day or two, and we’re down to 30%. That’s 400W / m2. A typical data centre will consume 4kW / rack. After allowing for the usual factors, each rack takes about 4-5 m2 of space, so say 1kW / m2. That means for every 1 m2 of IT load, we need 2.5m2 of solar capture. That’s a 2.5:1 ratio at best. In practice, it’s going to be much worse.
Hence we find ourselves on a trajectory back to off-setting.
But before we go there, perhaps we’re solving the wrong problem. And that’s for the next post,
Back to engineering, but first a disclaimer. Whatever numbers I use in this post are wrong. Photovoltaic technology (solar panels) and battery technologies are evolving so rapidly that everything is out of date as soon as it hits the market. So although I believe myself to have got the concepts right, the calculations are intended to show the type of calculation involved, but probably over-estimate the downside and under-estimate the upside. Having said that, the numbers are not order-of-magnitude wrong. They may be 10% or 20% out, but probably not much more.
The advantages of using solar are obvious: sunlight is – at least until the oil companies get their hands on it – free. Photovoltaic (PV) panels generate DC, not AC, and most of our load is DC. That’s a single conversion from photons to DC electricity, rather than from coal (or whatever) to steam to rotational kinetic to AC (via induction in an alternator) to DC, which will be inherently more efficient.
First, the footprint. The carbon footprint of PV panels is poorly understood. All we can say is that the numerator in any calculation consists almost entirely of non-renewables, so will asymptote to infinity. However, PV panels have indefinite life spans, which makes for an equally big denominator. So, overall, the green footprint asymptotes to ∞/∞=1. This is much better than hydrocarbons, for which the numerator is infinite and the denominator – burn it once and it’s gone – is finite.
Second, space. The amount of power a PV panel can generate is the solar radiation multiplied by the efficiency of the panel. In the tropics, the solar radiation is about 1,350kW / m2. I’m not sure how efficient the latest generation is, but let’s say about 30% (a wiki article says 20% is nearer the mark, but the article seems last to have been updated in 2014). To generate 1MW of power, therefore, we need 1MW / (1,350W/m2*30%) = 2,469 m2 of space. A typical data centre budgets 4kW per rack, so 1 MW is 250 racks, and at 5m2 / rack including non-white space, that’s 1,250 m2: although we don’t get quite enough power from putting the panels on the roof, nor do we have to buy vast tracts more land to put the panels on. Cover the car park and we’re done.
So far, so good. But, as any climate denier is quick to point out, the sun doesn’t shine at nights. If we’re to keep our data centre running 24/7 we need batteries.
In a conventional data centre, the batteries are expected to provide power in the brief gap between the primary power dropping out and the secondary power kicking in. As a result, batteries provide power for maybe ten minutes per incident, and there’s a gap of hours, if not days or months between incidents. In normal circumstances the time it takes to recharge the batteries doesn’t matter.
This is just as well, because it takes longer to recharge batteries than to charge them. However, if we’re running of PV panels, the power drops out every night, and we need to have the batteries re-charged and ready to go in time for the next night.
There’s a handy paper here which describes the calculations for lead-acid batteries, and the data sheet for a typical industrial scale battery is here (I am not advocating or advertising this battery – it’s just the first one on Alibaba that had a full spec sheet). Here are the calculations:
This is an Excel file you can download and play with. The measure of how long it takes to recharge a battery is its efficiency, and the handy paper says that lead-acid batteries are typically 65% efficient. The spreadsheet calculates the number of batteries needed based on that. The result is 1,667 batteries per MW using the batteries in the data sheet.
These are industrial, not car batteries, and weigh 175 kg a piece. 1,667*175kg is 291 tons of lead-acid battery to keep the data centre running 24/7. Furthermore, these batteries last 10-12 years, so need to be replaced once in the life of the data centre, so that’s 582 tons – imagine 350 crushed cars. And that’s for 1MW. The average data centre is more like 10MW, so that’s 3,500 crushed cars. Quarrying, shipping and destroying 5,800 tons of lead, acid and PVC casing has a pretty significant carbon footprint. And although Lithium-ion cells are more efficient, they come at a higher carbon footprint because, where lead is commonplace, lithium is rare.
The other problem is that we need to buy enough PV panels not only to power the data centre, but also to charge the batteries. As the batteries are 65% efficient, that implies that for every Watt of power, we need an additional Watt/.65 for charging, so we need (1+1/.65) * 2,469 m2=6,267m2 of panel per MW. For 10MW, we are buying vast tracts more of land than we’d otherwise need.
And, after all of this, if there are few days in a row of heavy cloud and little sun, all of the batteries will be exhausted and all this in vain.
What this comes down to is a physical manifestation of the abstract physics I mentioned some time back, that electricity is electrons in motion, and that storing electrons when they’re not in motion but in such a way that they can quickly be, is difficult. As a result, whatever greenness we gain by using PV panels, we lose in terms of the huge footprint in manufacturing all the batteries and extra panels we need to keep the data centre light at night.
So, it seems to me that compromise is needed. We operate the DC load from solar panels during sunny days, and from other sources at night and cloudy days. In our DC-only data centre:
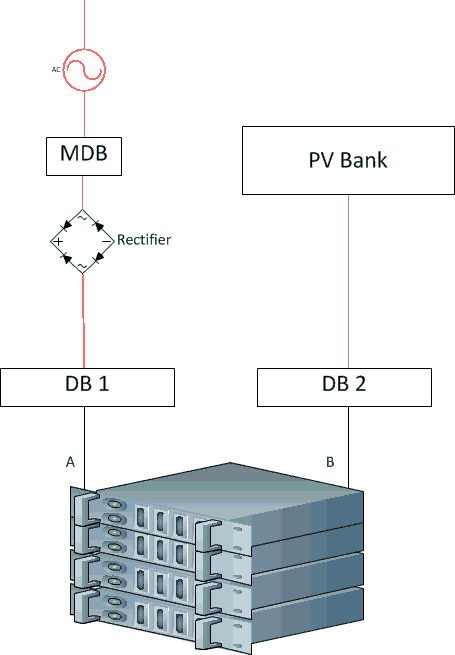
(If we stick with traditional AC PSUs, in the above and subsequent diagrams, remove the rectifier and put a DC-AC invertor in the PV line.)
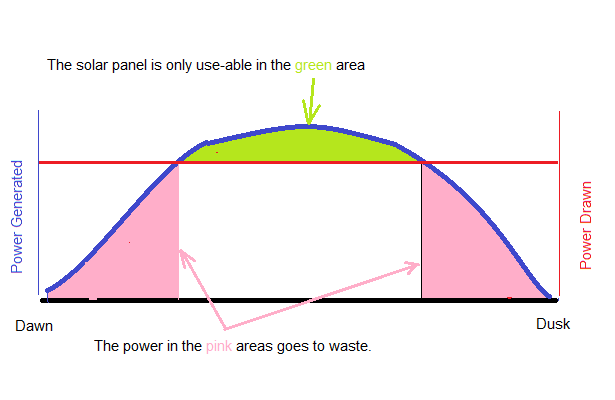
Unfortunately, this is too simple to work. At the start and end of the day, when the power available from solar cells is rapidly increasing or decreasing, even a single computer would have difficulty working out which supply to choose. This is because, unlike gen sets, which go from no power to flat-out almost instantaneously, solar panels energise in the same way that cups of water fill up. The power required by a computer is fixed, so a solar panel is useless to that computer until the panel is sufficiently energised to deliver all of the required power. If, for example, a single computer needs 350W, there’s no point in sticking 250W in the back: the computer won’t work. So we need to wait until the solar panel is fully energised before we can use it.
This means that all the power we could be using in the post-dawn and pre-dusk times goes to waste. In addition, on cloudy or rainy days, the panels may never become fully energised.
There’s a solution to this, which is called a DC combiner. This takes whatever power is available from the solar panels, and combines it with power from other sources. The resultant topology is something like this:
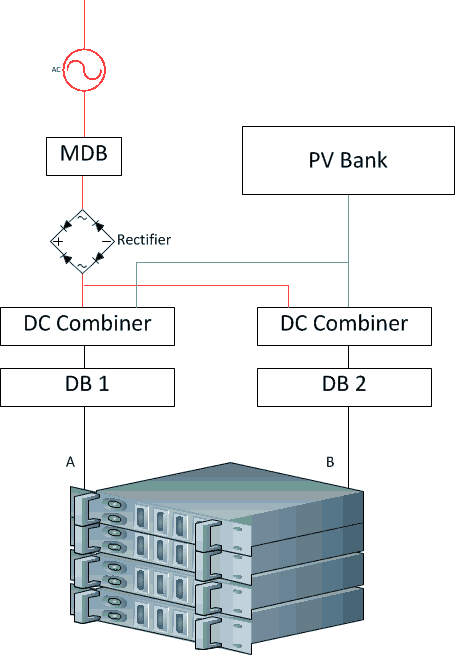
So each of the power rails combines power from conventional sources with solar power, and feeds that into the computers.
Unfortunately, the technology inside DC combiners has been patented (by Google amongst others – it’s nice to see my thoughts on DC are in good company). In an ideal world, owners of these patents would open source their DC combiners and we could take whatever we could get from the panels and make up the rest from other power sources.
In this non-ideal world, there remains a compromise. Each time the solar panels deliver a threshold amount of power, we use it, and each time they fall below, we switch back. As a graph over the course of a day:
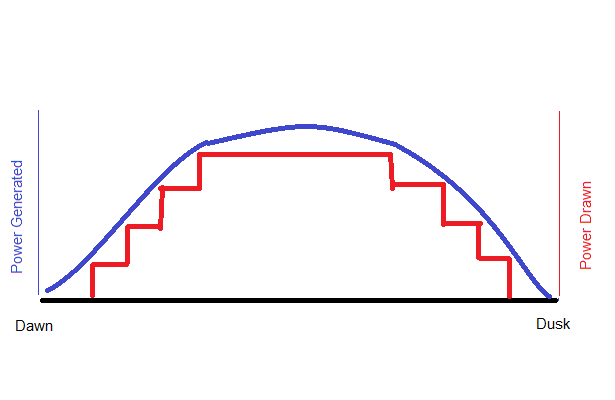
The smooth blue line is the total amount of power the panels generate. In and ideal (Google) world, we would draw the lot but, in our non-ideal world, we divide the DC load into evenly sized lumps – say 300kW / lump, and switch it over to solar power as and when the solar farm becomes sufficiently energised to power that lump. When the farm starts de-energising, we switch it back. On cloudy days, perhaps only 75% of the computers are solar-powered; at nights, 0% are.
The topology to support this is:
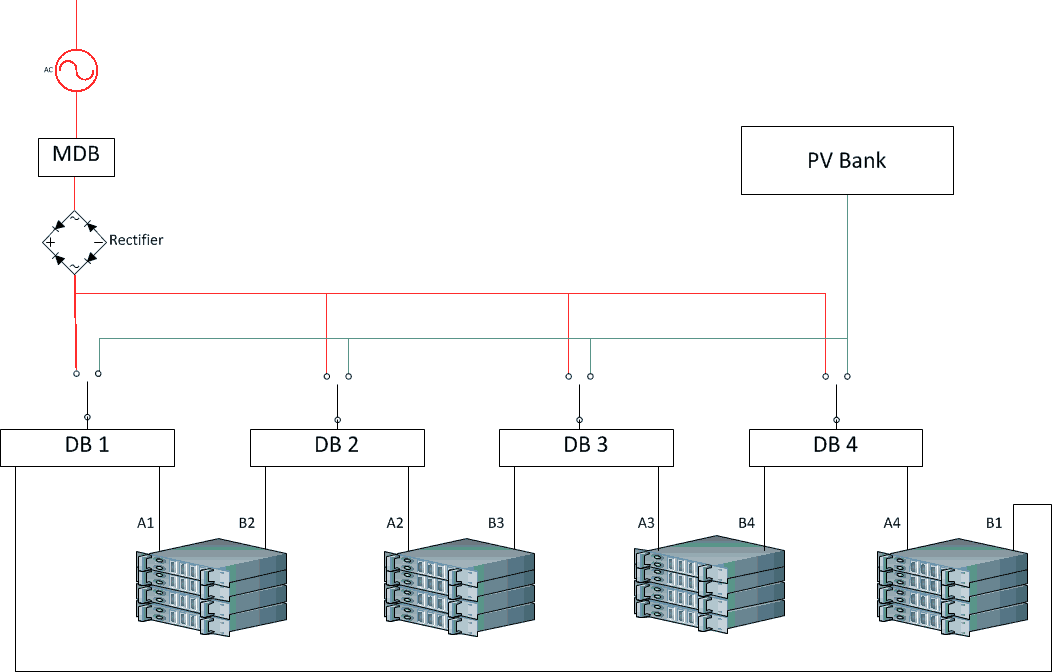
At the bottom, I’ve divided the IT load into four evenly balanced units. As one of the sizes in which off-the-shelf distribution panels come is 300kW, let’s say that each lump of IT load draws 300kW for a total of 1.2MW.
The AC power source at the top left includes gen sets, utility power and whatever: i.e. a reliable source of AC. I haven’t expanded this as I don’t want to clutter the diagram. The AC is converted, probably by multiple redundant rectifiers, into a reliable source of DC. This reliable source is distributed to four DBs, one for each lump of IT load.
At night, all IT loads run off conventional power. As the day starts, we wait until the panels are generating 25%, or 300kW, and switch the first load over. When the panels are up to 50%, we switch the second load over and so on – and in reverse at the end of the day. If it’s cloudy, we may never switch over all four loads and, if it’s really cloudy, we have to run off conventional power all day.
There would have to be a margin of error at the switch-to and switch-from points – for a 300kW IT load, perhaps we don’t switch to solar until we have at least 350kW spare, and we switch from solar if there is less than 325kW spare.
I’ve chosen four IT loads to keep the diagram simple. In practice, the size of the DBs would determine the number of IT loads and increment. As a flourish, I’ve also included full redundant paths just to show that this approach can yield them. And, yes, if it’s a conventional data centre with PSUs in the computers, scrub the rectifier, put an invertor (DC-AC convertor) after the solar panels, and everything will still work.
Cooling
Another possibility with solar panels is to forget about the IT, and use the panels to top up the power available to the cooling system, which will work much harder during the day. To do this, we put an invertor after the solar power to turn DC to AC. Combining two AC sources is straightforward as long as they are in-phase, and the invertors can deliver in-phase AC.
Follow-the-Clock Cloud Computing
A more radical solution – especially for cloud providers – is this: don’t run the data centre at all when it’s dark. Power the whole thing down and do the computing in the next time zone to the east in the morning and the west in the evening. This is especially viable for computing used by people (you know, human beings, on their phones and PCs), as (a) most people in TZ are asleep for the first few hours of daylight, so the cloud can compute for people to the east, and the converse at the end of the day.
* * *
This the best I can do on photovoltaic panels. The real problem with photovoltaic solar panels is that the sun doesn’t shine at night, and is diminished on cloudy days, so we either need to design around that, or we store electricity. As soon as we have to store electricity, we fight physics. The next post will look at a way around that.
Previous Next